


Primera parte Un fantasma recorre el universo de los textos. Un ejército de máquinas, a las que aludimos con metáforas zoológicas (arañas) o mecánicas (cosechadoras), merodean por la Red, leen nuestros textos, e incluso atisban por encima del hombro mientras escribimos. ¿Para qué lo hacen? ¿Para espiarnos? A veces… ¿Para comprendernos mejor? Ciertamente. ¿Para ayudarnos? […]
Primera parte
Un fantasma recorre el universo de los textos. Un ejército de máquinas, a las que aludimos con metáforas zoológicas (arañas) o mecánicas (cosechadoras), merodean por la Red, leen nuestros textos, e incluso atisban por encima del hombro mientras escribimos.
¿Para qué lo hacen? ¿Para espiarnos? A veces… ¿Para comprendernos mejor? Ciertamente. ¿Para ayudarnos? Eso dicen…
I
En el universo de la World Wide Web las máquinas (los ordenadores, o mejor dicho, sus programas) saltan constantemente de página en página a través de los enlaces, escudriñan su contenido y almacenan cada palabra y cada combinación. De esa forma, cuando les preguntamos (por poner un ejemplo): ¿dónde se habla de Hércules?, pueden contestarnos: aquí y allá…
Pero los buscadores también leen los textos que tienen los enlaces, y así se enteran de qué creen los autores (de páginas web, de cualquier documento accesible en la Red) que tratan las páginas a donde remiten… [2] .
Precisamente esa lectura de enlaces es la responsable de algunos de los hallazgos más asombros de los buscadores: encontrar lo que no está… Por ejemplo, la búsqueda de gentuza en Google:
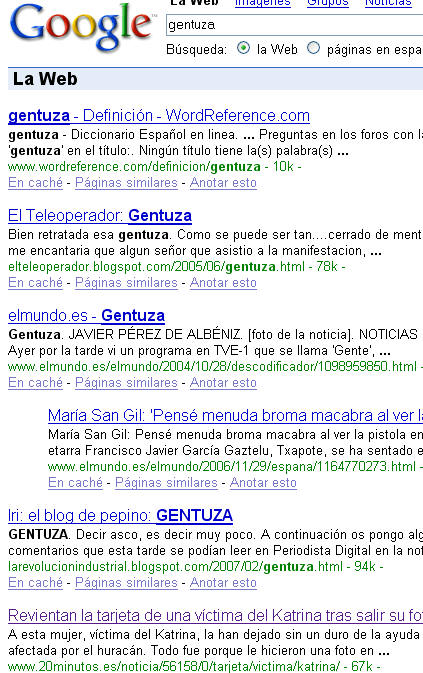
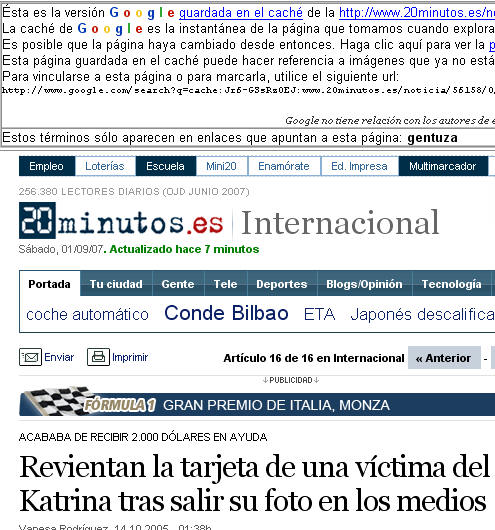
me llevó a esta noticia [3] ,

El texto (como advierte el buscador: «Estos términos sólo aparecen en enlaces que apuntan a esta página») no contiene la palabra en cuestión [4] :
Pero hay otras formas en las que las máquinas nos leen. Por ejemplo: cuando intermedian en los artefactos (hadware) que usamos para escribir. Ese es el caso de los softwares espías residentes en un ordenador (como Keystroke Spy [5] ), que supervisan todas las pulsaciones del teclado, y avisarán por email cuando su usuario teclee algo de interés [6] .
II
Ocasionalmente, las máquinas también escriben (o, para no exagerar: editan, ponen en contacto textos diversos). Ocurre, por ejemplo, cuando colocan dentro de las páginas web anuncios relacionados con su tema (que es lo que hace Google Adwords [7] ).
Para ello tienen que haber leído su contenido. Por ejemplo, en una página que analiza unos carteles amenazadores [8] aparecen estos anuncios [9] :
-
El centro del accidentado. Ayuda jurídica para víctimas de accidentes.
-
Chistes de abogados
-
Problemas con alquileres
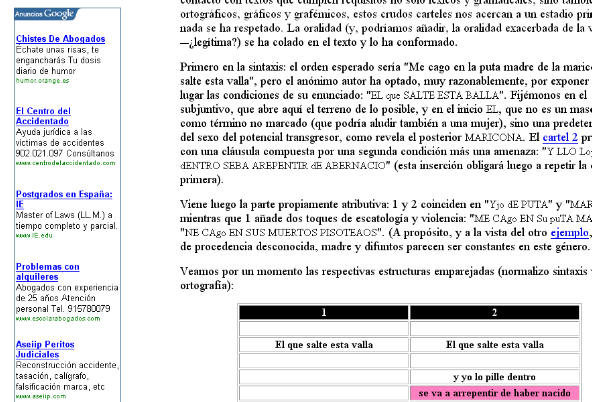
¿Por qué? El texto contenía términos como amenaza, insulto, violencia, transgresor o merodeador, junto a expresiones como «me cago en sus muertos». Los insondables algoritmos de Google Adwords han determinado que (entre los temas de publicidad que administran) los relacionados con accidentes, abogados y problemas eran los más pertinentes…
(Interludio filosófico)
Este tipo de comportamientos nos podría llevar a la siguiente cuestión. Sí: las máquinas leen nuestras páginas web, pero, ¿las entienden? En realidad, esto es una variante del Test de Turing [10] . Como se recordará, en dicha prueba un humano conectado a un terminal exclusivamente textual (tipo chat) debe determinar, sólo a través del diálogo, si al otro lado hay una máquina o un ser humano.
Uno dice «¡Gentuza!», y el buscador contesta: «Sí, como esos que estafaron a una víctima del Katrina…». Uno escribe «amenaza, violencia, transgresor», y los anuncios corean: «abogados, accidentes, problemas». ¿Nos están entendiendo las máquinas? Bueno: lo suficiente como para echarnos una mano. Y el éxito de los buscadores y de los programas de anuncios contextuales parecen indicar que lo logran…
Hay en marcha sistemas todavía más sofisticados. Por ejemplo: un programa que analiza, en un foro sobre valores bursátiles, cuál es la opinión generalizada sobre cuáles van a subir y cuáles a bajar. Es el Community Sentiment de Yahoo [11] . Un análisis de este estilo exige manejar un número considerable de variables semánticas y pragmáticas.

Pero hay que tener en cuenta que las máquinas no sólo están leyendo nuestras páginas web: también leen nuestros diarios (o blogs) o nuestro propio correo (en sistemas como Gmail [12] ). Y actúan en consecuencia; si recibimos un email que contiene la palabra México pondrán a su lado anuncios relacionados:
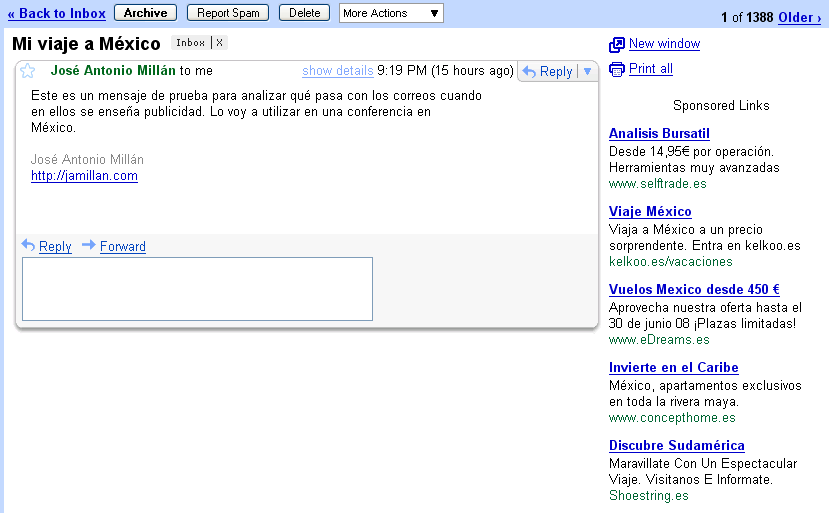
También leen nuestras notas personales (Google Bloc de notas [13] ), nuestra escritura manuscrita en una agenda electrónica (a través de programas como PenReader [14] ). Si además parece que están enterándose, ¿no supone esto un problema?
La verdad es que sí, pero también nuestros secretarios (o secretarias) leen nuestra correspondencia, y a ellos dictamos nuestras cartas [15] . Digamos que quien confía en ayudas externas (ya sean de carne y hueso o de código) debe atenerse a las consecuencias…
III
Y en este momento nos surge un tema de especial interés. Si las máquinas nos leen, ¿no habrá que tenerlas en cuenta cuando escribimos? La respuesta es claramente que sí: el autor o editor de cualquier material en la Web tiene que favorecer que le lean las máquinas, so pena de comprometer su propia difusión.
Un ejemplo particularmente ilustrativo es el de las licencias Creative Commons. Cada una de ellas tiene tres versiones:
-
el resumen, legible por humanos [16] . Dice cosas como:
-
el código legal, legible por abogados [17] ; éste es su comienzo:

-
el código digital, legible por máquinas [18] :
El código digital está destinado a ser leído por sistemas automáticos. En el caso de Creative Commons, se ha incluido para informar a los buscadores que quieran localizar contenidos con determinados tipos de licencia. Las personas no tienen por qué entenderlo, y ni siquiera leerlo: el texto no está visible en la página.
Al igual que este código, en las páginas web hay muchos elementos cuyos destinatarios son las máquinas: los ficheros robots.txt [19] , los metatags, y las palabras que se incluyen para forzar el spamdexing [20] . El webmaster (de ingenio aunque tramposo) que llena de palabras prometedoras la parte inferior de su página, y las escribe en el mismo color del fondo para que no se lean en la pantalla, sabe bien que no busca lectores humanos… En el terreno de la edición científica, los metadatos son un elemento básico del texto.
Y una última, pero importante consecuencia, para aquellos que escriben o editan en la Web: cada enlace es un voto a una página. Y mediante el texto específico que enlazamos estamos diciendo algo sobre la página de destino no sólo a nuestros lectores humanos, sino, sobre todo, a las máquinas.
Segunda y última parte
IV
Además de las búsquedas, que antes veíamos, las máquinas también están leyéndonos para ayudarnos con distintas tareas…
Los servicios de alertas, como Yahoo Alerts [21] , rastrean la prensa y otras páginas web para avisarnos de cuándo aparece alguna de las palabras clave que les hemos indicado. Resulta muy útil para tener controlada a una empresa rival, conocer los movimientos de una determinada persona, o sencillamente, ver qué dicen de nosotros (el llamado ego surfing).
Los lectores o agregadores de RSS (que suministran el contenido nuevo de sitios web, como Google Reader [22] ) leen los sitios que escogemos para enviarnos sus titulares junto con una porción mayor o menor de texto.
Los detectores de plagios, como Damocles [23] , comparan el texto que les sometamos con muchos otros dispersos por la Web, con el objeto de determinar si se han utilizado (sin citar) partes de otras obras.
Los sintetizadores de voz (como SodelsCot [24] ) leen los textos que les proponemos.
A veces su lectura no es muy buena, como los lectores que, ante un texto sin puntuación en la antigüedad clásica, leían «mutilando los pensamientos y pronunciando imperfectamente» [25] ), pero en ocasiones leen con mucha fidelidad. Tenemos testimonios de cómo los lectores de la antigüedad clásica servían, entre otras cosas, de ayuda a personas con problemas en la visión [26] , y ése es uno de los usos actuales de los conversores texto-habla.
Sin olvidar a los programas traductores (como SoftCatalà [27] , del catalán al castellano y viceversa), que leen nuestros textos para traducirlos.


Y por último, el sistema de espionaje anglosajón ECHELON [28] (gobernado por Estados Unidos, Canadá, Gran Bretaña, Australia, y Nueva Zelanda) o el sistema Carnivore [29] del gobierno de los Estados Unidos (FBI) escrutan las comunicaciones (correos electrónicos, por ejemplo) a la búsqueda de términos o nombres. Lo bajo de sus fines no debe hacernos olvidar la magnitud de la tarea que afrontan.

V
Hasta aquí nos hemos movido en un dominio, el digital, que posibilita que las máquinas nos lean directamente. En la página web los humanos vemos formas, desciframos signos y por último leemos palabras. Las máquinas también las leen, pero no por el dibujo que pintan en la pantalla (el cual puede cambiar según las preferencias de nuestro navegador), sino porque acceden al código que les representa. Por ejemplo: la H tiene el código hexadecimal 48, y el fragmento de código
%48%E9%72%63%75%6C%65%73
se leería HERCULES [30] . El sintetizador de voz que lee el documento de procesador de textos y el programa espía que supervisa nuestro correo acceden también únicamente al código de las letras.
En caso de contradiccion entre el mensaje visual y el código los humanos seguimos, por supuesto, lo que nos dicen nuestros ojos. Por eso en los años 80, para burlar la censura que supervisaba las BBS (tablones de anuncios electrónicos [31] ), los usuarios escribían sustituyendo letras por otros signos con los que tenían cierto parecido (pero que no compartían su código) [32] . Por ejemplo, para escribir similar se usaba la siguiente secuencia de caracteres:
51m1L4R
Lamentablemente, ya hay programas que leen también estas escrituras…
VI
Pero aparte de este acceso directo al código, las máquinas están leyendo cada vez más las publicaciones impresas.
La película Los tres días del cóndor de Sydney Pollack (1975) [33] se iniciaba con unas oficinas de la CIA en las que una máquina iba pasando páginas de los periódicos bajo el ojo escrutador de una cámara. Han transcurrido más de un cuarto de siglo desde entonces, y los programas ya son muy buenos leyendo libros y periódicos.
Pero hay dos formas en que las máquinas pueden tratar nuestros textos impresos. Una es fotografiando sencillamente el texto, es decir, describiendo pixel a pixel la traza de sus letras.

Arriba tenemos un fragmento del facsímil JPEG de la primera edición del Quijote en la Biblioteca Virtual Cervantes [34] . Debajo, las tres letras iniciales de la palabra Hercules descompuestas en pixels.

Describir la forma de los signos alfabéticos no es un comportamiento muy sofisticado. Es lo que hacía en el siglo V a.C. un pastor iletrado con las letras griegas que constituían el nombre TESEO ( ΘΗΣΕΥΣ ) en la tragedia perdida de Eurípides [35] :
No soy habilidoso en las letras, pero diré sus formas y claros signos. Hay un círculo, como trazado a compás; éste tiene una clara marca en el centro. La segunda letra tiene primero dos líneas, y otra las separa en el centro. La tercera es como un rizo de cabello, mientras que la cuarta, de nuevo, tiene una línea hacia arriba y tres que se apoyan en ella. La quinta no es fácil de explicar: hay dos líneas separadas, pero se encuentran en un soporte. La última letra es como la tercera.
El público ático del siglo V a.C. (ya parcialmente alfabetizado) podía reconocer las letras por las formas transmitidas. Pero el lector actual puede, más cómodamente, leer en la alineación de píxels:

Ahora bien ¿sabía leer el pastor de Eurípides? ¿Sabe leer el escaneador de páginas ante el que desfilaron las páginas del Quijote? Claramente, no. El portador de formas de letras no lee.
VII
Para que las máquinas lean de verdad hay que ir un paso más allá: Google Libros [36] (por poner un ejemplo bien conocido) está digitalizando libros de las bibliotecas. Pero además de fotografiar sus páginas les aplica un programa de reconocimiento óptico de caracteres (OCR).
A través de ese procedimiento, la máquina reconocerá la forma que «tiene primero dos líneas, y otra las separa en el centro» como una hache mayúscula (si el texto está en alfabeto latino) o como una eta mayúscula (si está en griego). Y así sucesivamente. Por ejemplo, sometamos el archivo con las palabras del Quijote de la Fig. 2 a un OCR accesible por línea [37] . Nos dará este resultado:
indufhia de Hercu-
Como vemos, puede haber errores. En este caso, la tipografía del XVII tiene ligaduras (como la que une s y t) que el programa no reconoce: en seguida veremos cómo lidiar con ellos. Pero en casos más modernos o claros la máquina puede leer todo el texto satisfactoriamente.
Al final del proceso, el OCR habrá extraído del «cuerpo» del libro (el papel y la tinta) su «alma», el conocimiento de la secuencia de caracteres que lo constituyen: la «acertada disposición del impresor y corrector», en palabras de un impresor del XVII [38] …
El OCR hace que los impresos se fundan en el continuum digital del que ya formaban parte las páginas web y otros archivos accesibles por Internet. Y cuando preguntemos: ¿en qué obras se encuentra la palabra «Hércules»?, acudirán a respondernos no sólo las páginas web, sino también las de los libros.
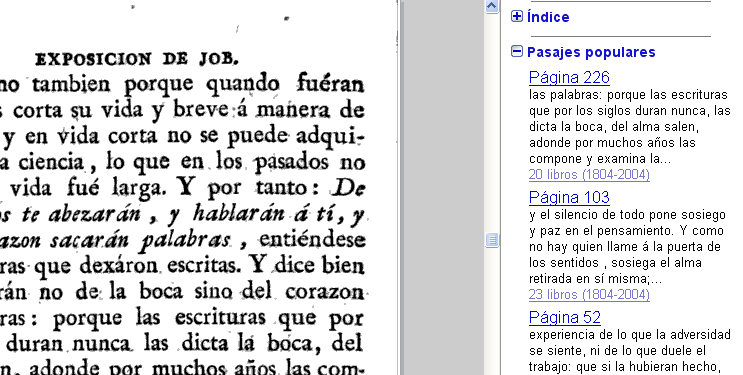
Al entrar en el universo de la imprenta, las máquinas pueden hacer averiguaciones suplementarias: por ejemplo, sus programas pueden rastrear qué pasajes de cada obra están citados en otros libros. Así, podemos enterarnos, por ejemplo, de que el famoso pasaje de la Exposición al Libro de Job de Fray Luis de León que reza [39] :
las escrituras que por los siglos duran nunca las dicta la boca, del alma salen, adonde por muchos años las compone y examina la verdad y el cuidado.
está citado en 13 obras más (de las que están en el fondo digitalizado por Google) [40] .
VIII
Por último, veamos cómo los humanos estamos, enseñando a las máquinas a perfeccionar su lectura.
Captcha [41] es el sistema mediante el que un sitio web con intervención del público se defiende de los programas que se dedican a introducir spam, proponiendo a los usuarios que tecleen el texto de una secuencia de letras deformada o borrosa que se les ofrece, como en este ejemplo de un blog:

Esta tarea exige (al menos por el momento) un ser humano, y en ese sentido es un test de Turing [42] . De hecho, sus siglas significan: Completely Automated Public Turing test to tell Computers and Humans Apart (Prueba de Turing pública y automática para diferenciar a máquinas y humanos).
Pues bien: también tenemos el reCaptcha [43] . Su peculiaridad es que el texto que propone para interpretación proviene del escaneado de libros: son palabras que el reconocimiento óptico de caracteres no acierta a interpretar (como industria, que veíamos anteriormente). El programa de OCR detecta una palabra problemática y reCaptcha la ofrece como clave de acceso, emparejada con otra palabra cuya interpretación se conoce (y que sirve de control).
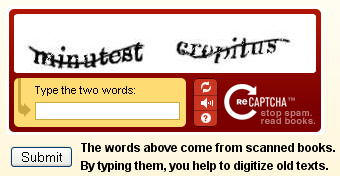
Las palabras dudosas se ofrecen cierto numero de veces, a distintos usuarios, hasta que la lectura se confirma.
ReCaptcha está funcionando por el momento como una ayuda para las digitalizaciones del Open-Access Text Archive [44] . Teniendo en cuenta que cada día se resuelven 60 millones de Captchas, que llevan de media 10 segundos, su suma daría 150.000 horas de trabajo al día, que reCaptcha pondría al servicio de la digitalización de libros.
y IX
…Y éste es el panorama: ejércitos de autómatas rastreando el ciberespacio y hordas de máquinas leyendo las bibliotecas. Programas que descifran letras y humanos que les ayudan, porque así se ayudan a sí mismos.
Más círculos: humanos que preguntan a la máquinas dónde están las cosas que les interesan, para luego escribir textos que leerán las máquinas para a su vez contarle a otros humanos de qué tratan.
Este espacio simbiótico de personas y máquinas, este continuum digital de textos y códigos es el caldo de cultivo de la cultura actual.
F I N
[1] Este texto comenzó como una conferencia en el Seminario Litterae de septiembre del 2007. Gracias a Antonio Castillo, Vanessa de Cruz y Emilio Torné por su invitación a participar. Agradezco a Javier Candeira por la ayuda para su preparación. Gracias a la invitación de Karim Gherab se convirtó en un artículo para Arbor. La versión actual se ha beneficiado de la presentación en varios foros: agradezco en especial a Ernesto Priani la invitación al Cuarto Foro de Edición Digital de México.
[2] El mejor texto sobre El modus operandi de los buscadores (o sea, de Google) sigue siendo el de Javier Candeira, «La Web como memoria organizada», en Revista de Occidente (Madrid), marzo del 2001 (versión electrónica en http://jamillan.com/para_can.htm).
[3] Búsqueda realizada el 14 de noviembre del 2007. 20 minutos, «Revientan la tarjeta de una víctima del Katrina tras salir su foto en los medios», 14 de octubre del 2005 (http://www.20minutos.es/noticia/56158/0/tarjeta/victima/katrina/).
[4] El hecho de que Google se dejara guiar por el contenido de los enlaces llevó al fenómeno de la «Google bomb»; desgraciadamente hoy parece que está inhabilitada por el buscador (http://en.wikipedia.org/wiki/Google_bomb).
[6] Los programas de espionaje también pueden registrar el ruido del teclado, y a partir de él deducir qué se está escribiendo (http://www.securitysolutionsmagazine.com/Articles/SSM38.pdf, pág. 22).
[9] A 13 de noviembre del 2007: los anuncios pueden cambiar cada vez que se accede a la página.
[10] A. M. Turing (1950) «Computing Machinery and Intelligence», en Mind 49: 433-460 (http://cogprints.org/499/0/turing.html).
[15] El rey de Aragón Pedro IV el Ceremonioso (siglo XIV) instituyó por primera vez la comunicación escrita para un gobierno peninsular, y también el archivo de los documentos reales. Se rodeó de una red de secretarios y escribanos, e incluso uno de ellos debía dormir por la noche en sus aposentos, «por si le venía la necesidad de escribir». Pero cuando quiso mantener secreto un tratado con el rey de Castilla lo escribió de su puño y letra. Véase Francisco M. Gimeno Blay, Escribir, reinar. La experiencia gráficotextual de Pedro IV el Ceremonioso (1336-1387), Madrid, Abada editores, 2006.
[18] Contenido en el código fuente de http://creativecommons.org/licenses/by/2.5/es/deed.es.
[19] http://www.webrecursos.com/pages/promo/promobot.htm. Curiosamente, una de las funciones de los robots.txt puede ser la indicación «No me leas»…
[20] Véase mi artículo «El libro de mil millones de páginas. La ecología lingüística de la Web», en Revista de Libros (Madrid), nº 45 (septiembre del 2000), y versión web en http://jamillan.com/ecoling.htm.
[25] Aulo Gelio, citado en Paul Saenger, Space Between Words. The Origins of Silent Reading, California, California, Stanford University Press, 1997, pág. 11.
[26] Raymond J. Starr, «Reading Aloud: Lectores and Roman Reading», en The Classical Journal, Vol. 86, No. 4 (Apr. – May, 1991), pp. 337-343.
[28] Véase el insustituible libro Echelon. La red de espionaje planetario (Barcelona, Melusina, 2007). Para un resumen, el artículo de la Wikipedia: http://es.wikipedia.org/wiki/ECHELON.
[29] Para un resumen, el artículo de la Wikipedia: http://es.wikipedia.org/wiki/Carnivore.
[30] ASCII table and description: http://www.asciitable.com/
[31] Véase el artículo de la Wikipedia » Bulletin Board System»: http://es.wikipedia.org/wiki/Bulletin_Board_System.
[32] Véase el artículo de la Wikipedia «Leet speak»: http://es.wikipedia.org/wiki/Leet_speak. Es también el procedimiento mediante el que los correos spam ocultan determinados nombres de marca al software censor, pero no al humano inquisitivo: » /!/6R/ «.
[34] P I, Capítulo I: http://www.cervantesvirtual.com/servlet/SirveObras/cerv/12371067559018288532624/ima0027.htm
[35] Traduzco del texto que presenta Niall W. Slater, «Dancing the Alphabet. Performative Literacy on the Attic Stage», en Epea and Grammata: Oral and Written Communication in Ancient Greece, Leiden/Boston, Brill, 2002, págs. 118-9. La asociación entre las formas de la letras y determinados objetos no se ha detenido en Grecia: véase el Abecedario industrial y del comercio: http://jamillan.com/abecedario/index.htm
[36] http://books.google.es/. Observo que estoy citando muchos productos de Google, aunque esto sólo demuestra una cosa: que esta compañía está en cabeza en el desarrollo y aprovechamiento comercial de las máquinas lectoras…
[37] Tesseract OCR, el mismo que usa Google (http://asv.aso.ecei.tohoku.ac.jp/tesseract/ ).
[38] Se trata de Alonso Víctor de Paredes. Sobre las relaciones entre continente y contenido en el libro véase mi artículo «Libro: el sarcófago abierto», en Trama y texturas (Madrid), nº 3 y versión web en http://jamillan.com/librosybitios/sarco.htm.
[40] http://books.google.es/books?qtid=cb7e7834&id=VTQ7lXB-ZmIC&as_brr=0. Se trata del recurso conocido como «Pasajes populares» de Google Libros.
[42] Por cierto: la versión para disminuidos visuales consiste en un audio que presenta, en medio de ruido de conversaciones, una serie de cifras. He aquí un ejemplo: https://www.blogger.com/captcha?type=AUDIO&captchaKey=1ql96hbcw21t0.
[43] http://recaptcha.net/learnmore.html. Recientemente ha sido adquirido también por Google.
Está sujeto a la licencia de Creative Commons «Reconocimiento-No comercial-Compartir bajo la misma licencia 2.5 España» (http://creativecommons.org/licenses/by-nc-sa/2.5/es/deed.es).
Puede comentarlo en el blog de Libros & Bitios.
La ilustración que encabeza este artículo procede de MMOArt, y proviene de Google Blogoscoped.
Fuente: http://jamillan.com/librosybitios/eramaq2.htm